本計劃前四期已發展出一套可供元富公司預測輪圈產品疲勞測試破壞、危險、或安全的計算機輔助分析程序,且已將該預測模式正式納入元富公司的開發程序中。然而隨著開發案件日益增加,這套計算機輔助分析程序仍然依據計劃初期所統計之28筆歷史測試資料進行破壞預測,對于不斷增加的實測資料,無法加以適當更新以得到更準確的預測結果。此外現有的破壞預測程序對于預測結果位于危險區的案件,僅能告訴工程師此設計“危險”,無法提供更明確的量化資訊,因此我們進一步提出「機率預測模式」來取代原先疲勞破壞預測程序,以改進前述這些問題。
本文第一節將討論舊有預測模式之優、缺點,以及實際使用上的問題;第二、三節則簡介機率預測模式的設計原理;第四節介紹機率預測模式的操作接口及使用方法;最后再針對未來發展方向作一討論。
1. 舊有輪圈疲勞破壞預測程序之優、缺點
舊有的輪圈疲勞破壞預測程序是以疲勞破壞理論搭配元富公司之歷史測試數據,作為判斷輪圈是否破壞之依據。如圖1所示,每一輪圈經過有限元素軟件作疲勞測試之模擬分析后,可以得到該輪圈在疲勞測試過程中之平均應力(mean stress)與應力振幅(stress amplitude),便可用一個資料點代表此輪圈繪于圖上,其中“×”表示實際測試破壞的輪圈,“○”表示實際測試通過的輪圈。依據元富公司所采用的鋁料為A356-T6之抗拉強度與疲勞限,在此圖上繪出Goodman線(如圖1中的藍色線)與Gerber線(如圖1中的紅色線)[Bannantine et. al, 1991],同時在經過與元富公司之歷史測試資料作對照后,訂定Goodman線與Gerber線之安全系數為2.6,如此將整個預測結果劃分為“Safe”、“Dangerous”、及“Failure”等三個區域,新開發的輪圈藉由有限元素分析計算所得到的平均應力及應力振幅數值,即可明確的在圖中得到一個預測結果,讓工程師一目了然地作為開發與否的參考依據。
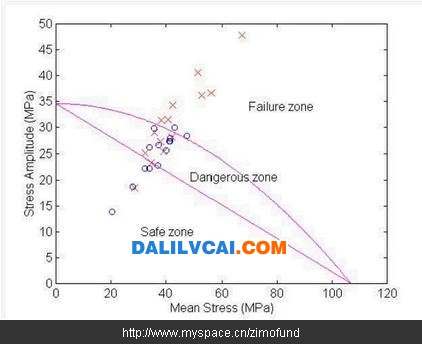 圖1. 舊有輪圈疲勞破壞預測程序之實際測試結果資料
圖1. 舊有輪圈疲勞破壞預測程序之實際測試結果資料
然而這個輪圈疲勞破壞預測程序仍然有以下幾點問題:
(1) 圖1所示的破壞預測準則是一非常明確(crisp)的預測模式,安全區、危險區與破壞區的區別是分別以明確的安全線與破壞線來劃分,對于在邊界附近的資料點預測可能不盡合理。
(2) 在危險區的資料點僅能宣稱其為“危險”,而無法提供比較明確的量化預測數據,以至于有部分輪圈的預測結果雖然位于危險區,甚至接近破壞區,工程師仍依其經驗進行開發,而且實際測試合格的不合理現象產生。
(3) 對于一個制程穩定的公司而言,歷史測試資料往往是最重要且最具有比對價值的,卻往往也是最容易被忽略的。本預測模式卻無法隨著實際測試資料數不斷增加而自我學習、調整,進一步提升預測正確率。
針對以上3項缺點,我們我們進一步提出機率預測模式,以元富公司不斷增加的歷史測試資料為比對標準,對每一個輪圈提供量化的“破壞機率”,而非破壞、危險、或安全,并以期望值的概念作為使用者對于該案件是否開發的判定依據。
2. 破壞機率預測模式
圖2為元富公司至目前為止累積之50筆實際測試資料,與圖1相同,橫坐標為平均應力值,縱坐標為應力振幅值,“×”表示測試破壞的輪圈,“○”表示測試通過的輪圈。由此圖中可以明顯看到,越往圖的右上方(平均應力、應力振幅越大),輪圈實際測試失敗的機率也越高。

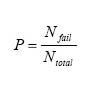

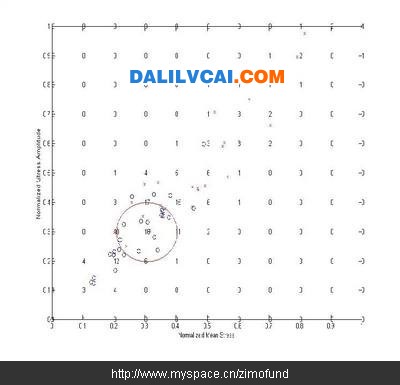
圖2. 所有實際測試的結果
新開發輪圈利用有限元素分析得到其平均應力與應力振幅,便可用一個資料點代表此輪圈繪于圖上,而利用歷史測試資料來預測此新開發輪圈之破壞機率,最直接的想法便是,對于圖2中一個新的資料點為中心畫一個半徑r的圓,此新資料點的破壞機率可定義為式(1)
其中Nfail為此圓內實際測試破壞之歷史資料點數,Ntotal為此圓內所有資料點數。
但是如此的定義在實務上有一個嚴重的問題,是如何決定此圓之半徑r。半徑r太大時,此圓將無法精確代表此新資料點,若半徑r太小時,在此圓內歷史資料數可能過少,計算出的破壞機率可能沒有意義。因此我們不直接以歷史測試資料預測新資料點之破壞機率,而是先將歷史測試資料繪成「破壞機率等高線圖」,新開發輪圈之資料點繪于此破壞機率等高線圖上,便可直接讀出新資料點之破壞機率。
3. 繪制破壞機率等高線圖
繪制破壞機率等高線圖前,首先將針對所有資料點之平均應力(X軸)及應力振幅(Y軸)以式(2)予以正規化:
圖3. 將平均應力及應力振幅正規化
接著將整個正規化后資料點的分布范圍劃分為一的網格,以網格節點為圓心畫一半徑為 之圓,統計此圓內測試通過及破壞之歷史資料,并以式(1)計算其破壞機率 ,則此破壞機率即為該網格節點之破壞機率。如圖3所示為設,后所得各網格節點之歷史資料數目。圖3中紅色圓圈即為以(0.3, 0.3)為圓心,所繪出之圓,于此圓中共計有歷史資料16筆,由此16筆資料所得之破壞機率即可被用來代表(0.3, 0.3)之破壞機率。依此方法可以計算出各網格點上之破壞機率如圖4所示。注意圖3中大部分的資料點分布在對角線,某些網格節點上所繪出之圓內歷史資料數過少甚至沒有,依據過少的歷史資料點所計算出的破壞機率可能完全沒有意義,因此此處設定一有效資料點數目N effective,圖4中網格節點上所包含之歷史資料數目少于設定之有效資料點數目Neffective,則在該網格節點上以“×”表示。圖4中為設定Neffective=0,亦即所有具有破壞機率之網格節點均被使用的狀況。
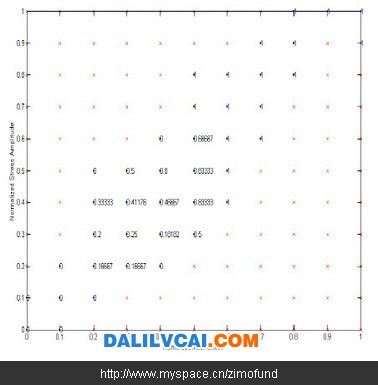
圖4. 各網格點的破壞機率值
獲得各網格點的破壞機率后,接下來將進一步以內、外插的方式,將破壞機率值擴展到全域,以繪出破壞機率等高線圖。有效資料點數目Neffective的設定將有助于避免圓內歷史資料數過少,使得計算出的破壞機率可能沒有意義的狀況發生。然而Neffective設的太高,將可能使得可計算破壞機率之網格節點數過少,導致后續將破壞機率值擴至全域的處理過程中,使數值演算不收斂而無法獲得破壞機率等高線圖。然而在歷史資料數還不足時,依據少數歷史資料計算出的破壞機率值有分布不平滑、甚至不合理的情況,因此在繪出破壞機率等高線圖前,我們加入了兩項工程上的判斷規則,來先對各網格節點的破壞機率值作平滑化的處理:
(1) 位于上方節點的破壞機率恒大于或等于位于下方節點的破壞機率。
(2) 位于右方節點的破壞機率恒大于或等于位于左方節點的破壞機率。
依據該兩項規則重新檢視圖4中各節點的機率值,其中網格點(0.4, 0.3)之破壞機率值小于其左方網格點(0.3, 0.3)之破壞機率值,顯然違背上述第二項規則,因此,該節點的機率值是不合理的,必須予以刪除。以此二規則刪除圖4中不合理的網格節點,如(0.4, 0.5)、(0.2, 0.5)等,得到修正后的實測破壞機率值如圖5所示。
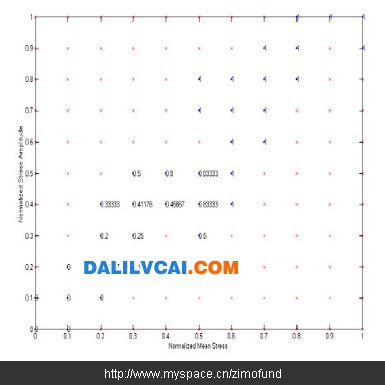
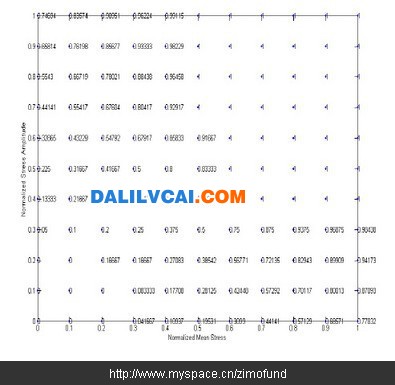
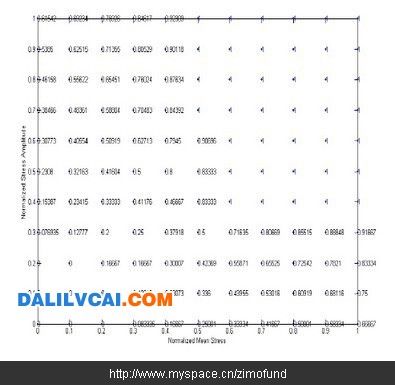 圖7. 最終迭代后的全域破壞機率值
圖7. 最終迭代后的全域破壞機率值
 圖8. 破壞機率等高線圖與舊有模式之比較
圖9. 輪圈破壞機率預測程序之操作接口
圖8. 破壞機率等高線圖與舊有模式之比較
圖9. 輪圈破壞機率預測程序之操作接口
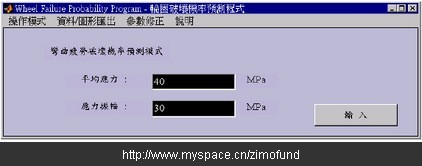
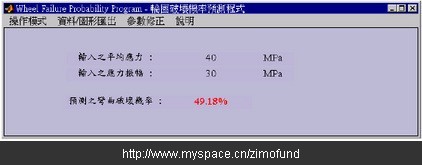
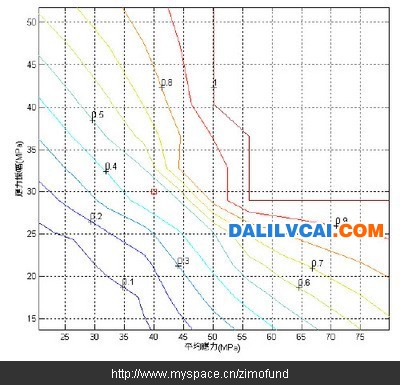 圖12. 預測彎曲破壞機率之等高線圖形
圖12. 預測彎曲破壞機率之等高線圖形
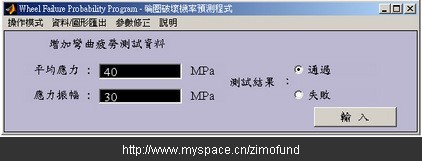
圖5. 修正后的實測破壞機率值
以圖5的破壞機率值為基礎,接著將用內插法與外插法,將破壞機率值擴展至全域,以繪出破壞機率等高線圖。注意這是一個迭代形式的過程,如圖6所示為經過一次迭代,將圖5中沒有破壞機率值的節點逐一以線性內插或外插求出后所得的結果,新數值加入后,下一次迭代再次重新逐一檢查每一節點,以線性內插的方式繼續調整每一節點上的破壞機率數值,但圖5中原先已有破壞機率數字之節點則不會被改變。如此不斷迭代,直到所有節點上的破壞機率數字都不再變化為止(如圖7)。運用圖7的結果,我們即可將全域的破壞機率值繪制成等高線圖,如圖8所示,此圖應是這組歷史資料點可以產生之最平滑的破壞機率等高線圖。
圖6. 第一次迭代后的全域破壞機率值
圖8的破壞機率等高線圖,即是對圖3中離散的歷史資料點資料所顯示“破壞可能性趨勢”的一個近似、量化的表現方式。圖3中大部分歷史資料點都集中在對角線附近,產生新的資料點時預期也會發生在目前資料點較密集的區域,而較不會發生沒有資料點或資料點較稀疏的區域。因此對于沒有資料點或資料點較稀疏區域平滑化處理的主要目的,完全在于產生較平滑之破壞機率等高線圖,精確度反而不是考慮的重點。
4. 對破壞機率等高線圖之闡釋
圖8中同時標示出舊有之破壞預測模式所使用的Goodman線(破壞線)與Gerber線(安全線),可以看出原先預測“破壞”之輪圈破壞機率在0.7以上,預測“安全”之輪圈破壞機率在0.2以下,而預測“危險”的輪圈,在圖8中可以讀出一個量化的破壞機率數字。
對于一個新開發的輪圈,機率預測模式將根據歷史測試資料預測出一個破壞機率值,與舊有明確、無彈性的預測模式有明顯的不同。圖8之破壞機率等高線圖也隨著實際測試資料的增加而不斷的更新,所有的歷史資料都會被有效的保存與運用。
在實際的開發經驗上,對于一件新的開發案,若沒有經過詳細的CAE預測,則往往容易因測試的不合格而不斷修改,一件開發案常常需要經過3至4次的試作才能成功進入量產。因此獲得一個新開發輪圈的破壞機率值之后,是否要接受這個設計繼續開發,還是應重新修改設計以降低破壞機率,這個判斷和元富公司對于新開發案試作次數的期望值有關。假設每一輪圈至多于第二次測試時均可通過測試,則從機率預測模式中得到破壞機率為Pfail的輪圈,其試作次數的期望值為(1-Pfail)+2Pfail。舉例來說,若公司的政策訂定每一新開發件的平均試作次數需在1.3次以下,則可得到Pfail=0.3,亦即當工程師進行CAE分析以及破壞機率預測后,必須以破壞機率為0.3的等高線作為是否開模的基準,當預測之破壞機率小于0.3時,即可進行實際之開模測試。
5. 破壞機率預測模式之操作接口
圖9為輪圈破壞機率預測程序之操作接口。主要操作模式可分為輪圈破壞機率預測模式及增加實際測試資料等兩大部分。在預測模式部分則包含了輪圈的三大測試,即彎曲、徑向及沖擊測試的破壞預測,此三項測試都將以機率預測模式來作預測,其中彎曲及徑向已分別有了完整的基礎資料可供使用,沖擊測試部分則仍待建立。
假設某個輪圈的平均應力為40Mpa,應力振幅為30Mpa。如圖10分別輸入平均應力及應力振幅數值后,經過與資料庫的比對計算后,分別得到如圖11的破壞機率值49.18%,及如圖12以紅色“□”表示的破壞機率等高線位置圖。
圖10. 輸入平均應力及應力振幅數值
圖11. 預測彎曲破壞機率輸出結果
于前段中提到,舊有預測模式無法隨著實際測試資料數不斷增加而自我學習、調整,進一步提升預測正確率,因此,在機率預測模式中加入了“增加實際測試資料”的功能,其輸入界面如圖13所示,只要有實際測試的結果,就可以分別加以輸入并更新資料庫(如圖14),藉由此一功能即可將實測資料不斷累積,進一步提升預測的準確性。
圖13. 增加實際測試資料輸入接口
圖14. 實測資料輸入接口